今天是個美麗的錯誤,本來預計將昨日寫好的 Encoder 、Decoder 、 LuongAttention 類別整合進單一個繼承自 tensorflow.keras.Model 的模型類別,只可惜一直無法成功除蟲
由於 Keras API 是基於 Tensorflow 框架的高階函式庫,要自行定義模型類別,需要對於 Tensorflow 的變數型態有基本的掌握,今日就無法產出有質量的內容了。因此我後來還是選擇了直接呼叫 Keras 的 functional APIs 來建模,並比較它們在同一份文本上預測精準度的差異。
我們一樣使用之前的英文-西班牙文雙語平行語料庫進行訓練:
使用 Luong 注意力機制的 Encoder-Decoder 訓練歷程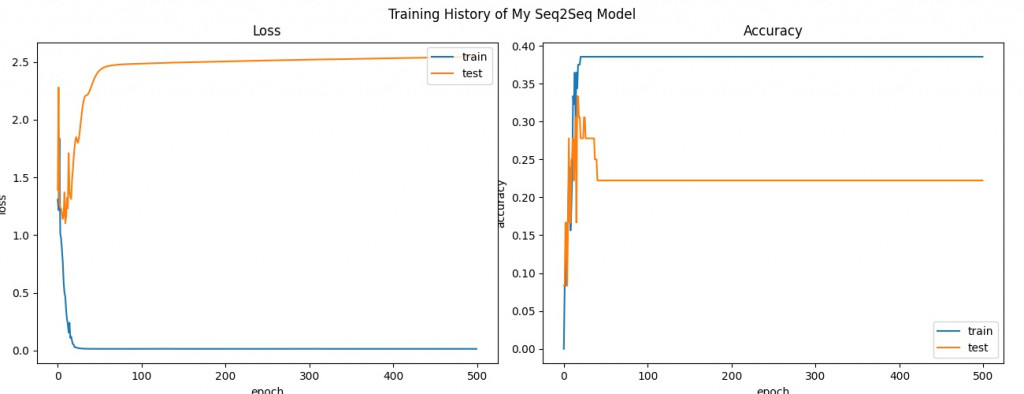
未使用 Luong 注意力機制的 Encoder-Decoder 訓練歷程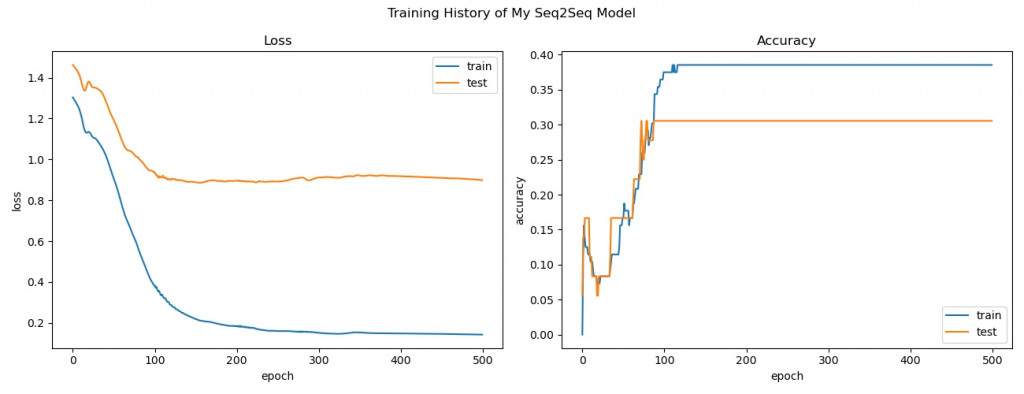
關於 Seq2Seq 的專篇討論就到此告一段落,明天我將會重新回溯資料的準備以及機器學習的訓練及推論流程,並著手進行中文-英文語料庫的文本處理,建立翻譯器所需之訓練資料。大家晚安!

